
首先先说结论:多线程>单线程,批量插入>单独插入
如何向数据库中插入数据?方法有很多种,比如:编写sql语句,使用工具导入(poi,easy excel),内存计算处理,使用数据库连接工具从其他库中导入(相同类型数据库,相同的表)等等
如何向数据库中快速插入数据? 当数据比较多时每条数据单独插入就不太适用了,因为每条数据都会占用数据库的一个连接,当数据库连接满了后其他应用或者服务就无法使用数据库了,只能等待有空余的连接时才能继续访问并且对于数据库的压力也是很大的(同时也和数据库的硬件配置有关)。这个时候批量插入就很有优势,mybatisplus提供了一套方法可以批量操作数据,例如:saveBatch方法,默认一批可以存放1000条数据,同时也可以自己定义存放条数
default boolean saveBatch(Collection<T> entityList) {
return this.saveBatch(entityList, 10000);
}但是在测试批量插入数据时速度并不快,根据实现的方法中可以看出,方法内会将获取到的数据集合分批执行插入操作,每批数量由batchSize控制,在每个批次中,saveBatch 方法会逐个插入实体对象(调用ibatis的sqlSession.insert(sqlStatement, entity)方法)
public boolean saveBatch(Collection<T> entityList, int batchSize) {
String sqlStatement = this.getSqlStatement(SqlMethod.INSERT_ONE);
return this.executeBatch(entityList, batchSize, (sqlSession, entity) -> sqlSession.insert(sqlStatement, entity));
}
protected String getSqlStatement(SqlMethod sqlMethod) {
return SqlHelper.getSqlStatement(this.mapperClass, sqlMethod);
}这里借助csdn博主总是学不会.的一些观点:
优势
- 简便易用:无需手动编写 SQL,直接调用接口方法即可。
- 自动事务管理:内置事务支持,确保数据一致性。
缺点
- 性能有限:底层逐条插入,面对大数据量时效率较低。
- 批量大小受限:默认批量大小可能不适用于所有场景,需要手动调整。
但是并不是说无法优化,在csdn博主总是学不会.的文章中有所说明优化办法:
1.配置数据库连接参数(注意:如果你的链接中已经配置了其他参数,注意参数与参数之间使用&符进行连接)
spring.datasource.url=jdbc:mysql://localhost:3306/your_database?rewriteBatchedStatements=truerewriteBatchedStatements=true 是 MySQL JDBC 驱动中的一个重要参数,用于优化批量插入(Batch Insert)操作的性能当 rewriteBatchedStatements=true 时,JDBC 驱动会重写批量插入语句,将多个 INSERT 语句合并到一个 SQL 语句中执行。这种方式可以显著减少与数据库服务器的通信次数,从而提高插入性能。
具体来说,驱动会将多个插入语句合并成一条 INSERT INTO table_name (column1, column2) VALUES (value1, value2), (value3, value4), ... 语句。
但需要注意:
兼容性
1.确保使用的是 MySQL 5.1.13 或更高版本,因为在此之前的版本中,该参数可能不会生效或存在兼容性问题。
事务处理:
2.如果在事务中进行批量插入,确保 rewriteBatchedStatements=true 不会影响事务的一致性和隔离性。
这里贴出csdn博主总是学不会.的文章可以作为参考,对于MybatisPlus批量插入与优化讲解的非常详细https://blog.csdn.net/m0_70871140/article/details/142731767
除此以外当数据量更加庞大时这种串行执行的方式就不再适用了, 可以考虑使用多线程的方式在批量插入的基础上并行执行插入操作提升执行效率。这里先贴出代码,后面再一步一步进行讲解
/**
* 插入数据 多线程执行
*/
@Test
void concurrencyInsertUsers() {
//记录执行时间
StopWatch stopWatch = new StopWatch();
//开始记录时间
stopWatch.start();
//每批插入50000条数据
final int batch_insert = 50000;
//创建一个异步任务列表
List<CompletableFuture<Void>> futures = new ArrayList<>();
//创建一个线程池
ThreadPoolExecutor threadPoolExecutor =
new ThreadPoolExecutor(Runtime.getRuntime().availableProcessors()*2,
80,
10000,
TimeUnit.MINUTES,
new ArrayBlockingQueue<>(1000));
//循环插入数据
int j = 0;
for (int i = 0; i <20; i++) {
// 创建一个用户列表,用于存储一批用户数据
ArrayList<User> userList = new ArrayList<>();
do {
j++;
User user = getUser(j);
userList.add(user);
} while (j % batch_insert != 0);
// 创建一个异步任务,并将其添加到futures列表中,为任务创建一个线程池
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
System.out.println("线程"+Thread.currentThread().getName()+"执行");
userService.saveBatch(userList, 10000);
userList.clear();
}, threadPoolExecutor);
// 将异步任务加入到futures列表中
futures.add(future);
}
// 执行所有异步任务
CompletableFuture.allOf(futures.toArray(new CompletableFuture[]{})).join();
//记录执行时间
stopWatch.stop();
System.out.println("执行最终用时:"+stopWatch.getTotalTimeMillis());
}
private static User getUser(int i) {
User user = new User();
user.setUserPassword("5d71a8404f4c47a213b11f2b178b4eb5");
user.setUserCode("test"+ i);
user.setUserName("测试"+ i);
user.setUserEmail("test@qq.com");
user.setUserPhone("13800138000");
user.setUserSex(1);
user.setUserAvatarUrl("https://example.com/avatar");
user.setRemark("test");
user.setUserStatus("1");
user.setIsDelete(0);
user.setCreateTime(new Date());
user.setUpdateTime(new Date());
user.setTags("");
return user;
}首先来说一下什么是多线程?它的流转过程是什么样子的?
生命周期:
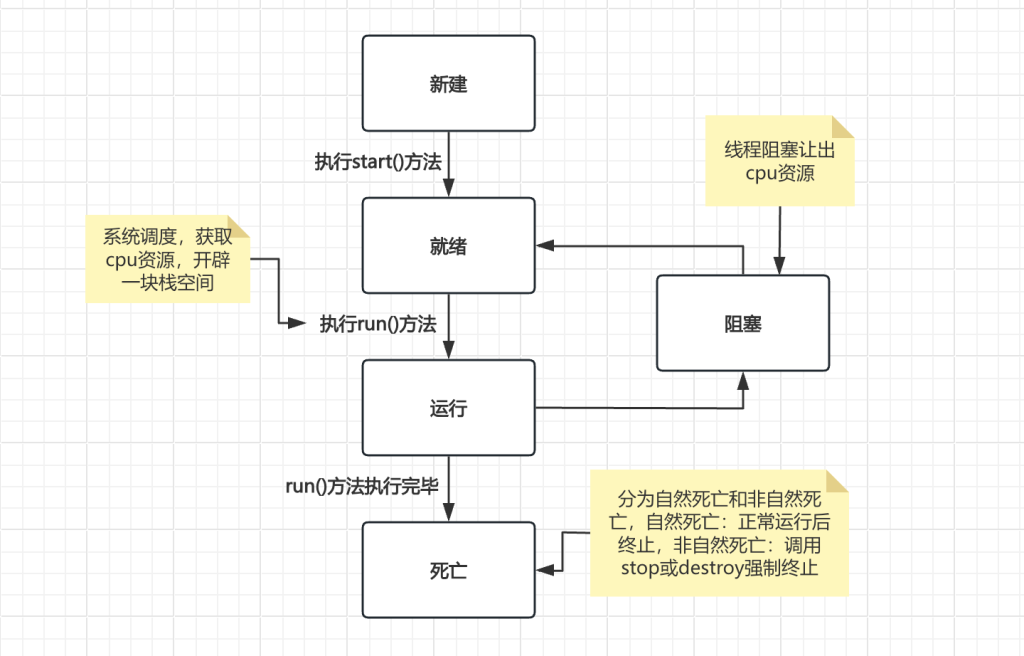
新建(new Thread)当创建Thread类的一个实例(对象)时,此线程进入新建状态(未被启动)。
就绪(runnable)线程已经被启动,正在等待被分配给 CPU 时间片,也就是说此时线程正在就绪队列中排队等候得到 CPU 资源。
运行(running)线程获得 CPU 资源正在执行任务( run() 方法),此时除非此线程自动放弃 CPU 资源或者有优先级更高的线程进入,线程将一直运行到结束。
堵塞(blocked)由于某种原因导致正在运行的线程让出CPU并暂停自己的执行,即进入堵塞状态。
死亡(dead)当线程执行完毕或被其它线程杀死,线程就进入死亡状态,这时线程不可能再进入就绪状态等待执行。
也就是说,当一个线程如果运行很顺利的情况下,会经过新建->就绪->运行->死亡这几种状态,但是当在运行过程中由于某种原因导致线程让出cpu并暂停自己就会进入阻塞状态,直到获取cpu资源后继续执行。
当线程死亡后,就会进行销毁,但是如果存在需要大量线程去执行的场景时,线程出现不正常的状态,导致栈内存空间不断堆积无法释放很容易破坏程序的稳定性以及健壮性,为了解决这类存在的问题或是资源没有良好利用的问题引入了线程池的概念
线程池中的数据流转:
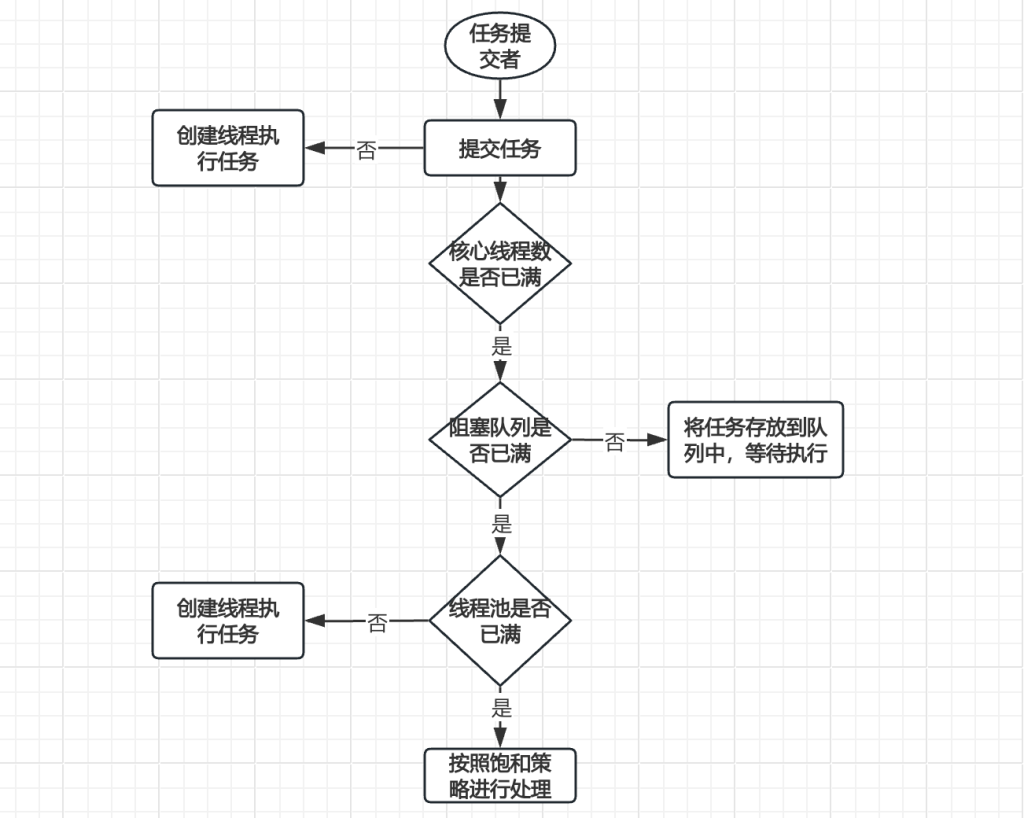
首先由任务的提交者提交任务,当任务提交后首先会查看核心线程中是否存在可用的线程,如果存在就创建线程执行需要执行的任务,当发现核心线程中已经没有可以使用的线程后,这部分没有执行的任务会查看队列中是否还有空的位置能够排队,如果能够排队则进行排队等待分配线程进行执行,如果队伍已经满了,则查看线程池是否也满了,如果线程池中还有可用的线程,则创建线程执行任务,如果线程池中也满了则会交由饱和策略进行处理(默认抛出),可以看出,在线程池中,做了多种机制为任务进行缓冲与兜底,同时也能有效的利用资源提升执行效率。
在线程池中存在几个核心参数:
核心线程数:
核心线程数是线程池中保持存活的最小线程数即使这些线程处于空闲状态(没有执行任何任务),线程池也会保持至少有 corePoolSize 个线程存活
其特点为:
1.在没有任务执行时,核心线程不会被销毁,会一直保持活动状态
2.当有新任务提交时,如果当前活跃的线程数小于 corePoolSize(核心线程数没满),即使任务队列中有任务等待,线程池也会优先创建新的核心线程来执行任务,而不是将任务放入队列。
如何确定corePoolSize线程数?
一般来说会将任务分为io密集型还是cpu密集型,通俗来说io密集型多偏向网络传输,文件、数据等多io操作而cup密集型就是指任务多偏向在内存中进行处理与计算,根据不同的类型对corePoolSize线程数进行计算,对于cpu密集型较多的任务一般定义为与cpu相同的线程数而io密集型则是cpu线程数的两倍或两倍减一(有一个线程数主线程)这样定义是由于io密集型的负载并不在本地,所以压力不会很大。我们可以通过java自带的工具包中的一个方法获取到执行当前任务的这台机器上的cpu核心数是多少,从而不用再换不同服务器时再次对其调整
Runtime.getRuntime().availableProcessors();源码以及注释:
/**
* Returns the number of processors available to the Java virtual machine.
*
* <p> This value may change during a particular invocation of the virtual
* machine. Applications that are sensitive to the number of available
* processors should therefore occasionally poll this property and adjust
* their resource usage appropriately. </p>
*
* @return the maximum number of processors available to the virtual
* machine; never smaller than one
* @since 1.4
*/
public native int availableProcessors();最大线程数:
最大线程数就是当队列中放不下且核心线程数也满了的时候的一个兜底,是指线程池中能容纳的最大线程数量,线程池会创建额外的线程,直到线程总数达到最大线程数
特点:
1.当核心线程都在忙碌,且任务队列已满时,线程池会创建非核心线程来执行任务。非核心线程一旦空闲且超过存活设置的时间,则会被回收。
2.非核心线程的存在是为了应对短期的突发任务需求,提升线程池的并发能力。
3.当线程池中线程数达最大线程数时,如果继续有新任务提交,而任务队列又满了,则根据拒绝策略处理(如抛出异常、丢弃任务等)。
队列(阻塞/普通):
分为阻塞队列与普通的队列(LinkedList/ArrayList)相比,支持在向队列中添加元素时,队列的长度已满阻塞当前添加线程,直到队列未满或者等待超时;从队列中获取元素时,队列中元素为空 ,会将获取元素的线程阻塞,直到队列中存在元素 或者等待超时。
使用场景:
普通队列(Queue)
适用于单线程环境: 用于简单的先进先出(FIFO)数据结构。
不需要阻塞等待: 适用于不需要等待队列可用或队列元素可用的情况。
阻塞队列(Blocking Queue)
适用于多线程环境: 常用于生产者-消费者模式,生产者线程可以将元素添加到队列中,消费者线程可以从队列中取出元素。
需要阻塞等待: 适用于需要等待队列空间或等待队列元素的场景,如任务调度、消息传递等。
线程安全性:
非线程安全: 普通队列通常不是线程安全的,如果在多线程环境中使用,需要手动进行同步控制。
阻塞队列(Blocking Queue)
线程安全: 阻塞队列是线程安全的,支持多线程并发操作,内部实现了必要的同步机制,无需外部同步。
在JUC包中常用的阻塞队列包含ArrayBlockingQueue/LinkedBlockingQueue/LinkedBlockingDeque等,从结构来看都继承了AbstractQueue实现了BlockingQueue接口(LinkedBlockingDeque是双向阻塞队列,实现的是BlockingDeque接口),在BlockingQueue接口中定义了几个供子类实现的接口,可以分为3部分,puts操作、takes操作、其他操作。
阻塞队列ArrayBlockingQueue与LinkedBlockingQueue的区别:
LinkedBlockingQueue 和 ArrayBlockingQueue 都是 Java 中 java.util.concurrent 包提供的阻塞队列实现,用于多线程环境下的并发操作。它们之间的主要区别在于底层数据结构的实现方式以及一些特性和行为上的差异。
底层数据结构
LinkedBlockingQueue:基于链表实现的有界/无界阻塞队列。内部使用一个双向链表来存储元素。链表的每个节点(Node)包含一个元素和指向前驱和后继节点的指针。
ArrayBlockingQueue:基于数组实现的有界阻塞队列。内部使用一个固定大小的数组来存储元素,并且在创建时必须指定数组的大小。
容量
LinkedBlockingQueue:可以是有界的,也可以是无界的(默认是无界的)。对于有界的 LinkedBlockingQueue,可以在创建时指定容量;对于无界的 LinkedBlockingQueue,容量为 Integer.MAX_VALUE。
ArrayBlockingQueue:始终是有界的,创建时必须指定容量,且容量一旦确定就不能更改。
线程安全性
两者都是线程安全的,都使用了内部锁(ReentrantLock)来保证线程安全性。
性能
LinkedBlockingQueue:在插入和删除元素时,由于使用链表结构,不需要移动元素,因此插入和删除操作的性能较高。但由于链表的节点需要额外的指针,因此内存占用可能较高。
ArrayBlockingQueue:插入和删除元素时,由于是基于数组的,可能需要移动元素,因此性能略低于 LinkedBlockingQueue。但由于数组结构的内存连续性,内存占用相对较低。
公平性
ArrayBlockingQueue:可以选择是否使用公平锁(fair lock),即先到先得的原则(默认是非公平的)。使用公平锁会增加等待线程的等待时间,但可以避免线程饥饿。
LinkedBlockingQueue:默认情况下是非公平的,不支持公平锁的配置。
使用场景
LinkedBlockingQueue:适用于需要高吞吐量的场景,特别是在队列长度可能不确定或动态变化的情况下。
ArrayBlockingQueue:适用于需要固定队列大小的场景,特别是在内存占用和性能之间需要平衡的情况下。
总结:LinkedBlockingQueue适用于动态队列大小,高吞吐量的场景,ArrayBlockingQueue适用于固定队列大小,对内存占用有一定要求的场景。
为什么使用多线程?
根据上面的描述可以知道,线程池是一个存放线程并可以持续利用的工具,有着很多参数与策略用于提升任务的效率与程序的性能。
下面对于我使用的多线程插入数据的方法进行一个讲解:
首先使用StopWatch类对执行时间进行一个记录:
//记录执行时间
StopWatch stopWatch = new StopWatch();这里没有使用默认的线程池(ForkJoinPool),因为某些情况下可能会存在一些问题(当CPU核心数-1大于1时,才会使用默认的线程池,否则将会为每个CompletableFuture的任务创建一个新线程去执行,也就是说,假如我们将服务从一台机器迁移至另外一台机器时,碰巧这台机器的cpu只有2个核心,这时则不会使用默认线程池而是直接创建线程任务,一般来说使用默认线程池的场景更多是以cpu密集型的任务为主)这部分的详细解读可以参考这位博主的文章:https://www.cnblogs.com/blackmlik/p/16098938.html
由于是对数据库的写操作,所以是以io密集型为主,这里定义了核心线程数为cpu核心数的2倍(或者可以定义为cpu核心数的2倍减1),最大线程数则设置为cpu核心数的2到4倍,阻塞队列这里由于没有较大并发或者海量数据的场景,所以选用了固定可控的阻塞队列。
//创建一个线程池
ThreadPoolExecutor threadPoolExecutor =
new ThreadPoolExecutor(Runtime.getRuntime().availableProcessors()*2,
80,
10000,
TimeUnit.MINUTES,
new ArrayBlockingQueue<>(1000));创建CompletableFuture异步任务,在异步任务中使用我们自己创建的线程池,在任务中进行批量插入数据,并将创建好的任务添加到一步任务列表中,从代码中可以看出,我是将数据拆分成了20个异步任务,放入到列表中,每批插入50000条数据,一共一百万条数据
//创建一个异步任务列表
List<CompletableFuture<Void>> futures = new ArrayList<>();
//循环插入数据
int j = 0;
for (int i = 0; i <20; i++) {
// 创建一个用户列表,用于存储一批用户数据
ArrayList<User> userList = new ArrayList<>();
do {
j++;
User user = getUser(j);
userList.add(user);
} while (j % batch_insert != 0);
// 创建一个异步任务,并将其添加到futures列表中,为任务创建一个线程池
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
System.out.println("线程"+Thread.currentThread().getName()+"执行");
userService.saveBatch(userList, 10000);
userList.clear();
}, threadPoolExecutor);
// 将异步任务加入到futures列表中
futures.add(future);
}最后执行任务列表中的任务
// 执行所有异步任务
CompletableFuture.allOf(futures.toArray(new CompletableFuture[]{})).join();
//记录执行时间
stopWatch.stop();
System.out.println("执行最终用时:"+stopWatch.getTotalTimeMillis());但是当我正执行时发生了报错
java.util.concurrent.CompletionException: org.springframework.transaction.CannotCreateTransactionException: Could not open JDBC Connection for transaction; nested exception is java.sql.SQLTransientConnectionException: HikariPool-1 - Connection is not available, request timed out after 30006ms.
报错原因:应用程序在尝试获取数据库连接时遇到了问题,具体表现为连接池中的连接已经耗尽,且在超时时间(30,006毫秒)内无法获得可用连接。
于是第一时间查看了mysql的最大连接数
SHOW VARIABLES LIKE 'max_connections';
那问题就来了,我实际使用了100个且都还是异步的,不应该出现耗尽的问题,仔细查看是连接池中的连接数已经耗尽,于是调整了连接池的最大连接数
hikari:
idle-timeout: 600000 #空闲连接
minimum-idle: 10 #最小空闲连接
maximum-pool-size: 40 #最大连接数
max-lifetime: 30000 #不能小于30秒,否则默认回到1800秒出现 SQLTransientConnectionException: HikariPool-1 – Connection is not available 异常通常是由于连接池中的连接耗尽或连接获取超时导致的。解决这个问题需要从连接池配置、数据库性能、代码逻辑等多个方面进行排查和优化。通过调整连接池配置、优化数据库操作和检查数据库服务器性能,可以有效减少此类异常的发生。而我这里经过排查发现就是因为连接池的最大连接数设置的不合理导致的
最终100w条数据插入的时间是:
执行最终用时:35890这里对连接池的最大连接数又做了一些调整
maximum-pool-size: 110 #最大连接数100w条数据插入的时间是:
执行最终用时:30821发现可以在30s左右插入100w条数据,但是这里要注意,在真正的生产场景中是需要根据业务场景去做调整的,这里只是理想状态下让任务跑在了自己设定好的“舒适区”,这样是可以更快的完成这个快速插入大量数据的任务,但是在执行任务的这一时刻,有其他的服务或者其他的任务在使用则可能会出现问题,对于Spring Boot Hikari连接池,在正式环境中其实可以使用动态调整的方式去自动调整最大连接数,这样在多服务使用同一个数据库的场景下也会减缓或者说提高连接池的利用率。
可以借助Spring Boot的@Scheduled注解,定期调节连接池参数,这里参考了博主的文章:https://blog.51cto.com/u_16175520/11678069
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Service;
@Service
public class ConnectionPoolAdjuster {
@Autowired
private HikariDataSource dataSource;
@Scheduled(fixedRate = 60000)
public void adjustPoolSize() {
int currentActive = dataSource.getHikariPoolMXBean().getActiveConnections();
int maxPoolSize = dataSource.getMaximumPoolSize();
// 根据当前活动连接数调节最大连接池大小
if (currentActive > maxPoolSize - 2) {
int newSize = maxPoolSize + 2;
dataSource.setMaximumPoolSize(newSize);
System.out.println("Increasing max pool size to: " + newSize);
}
}
}所以从上面的结果以及反应来看,并不是一蹴而就的,而是需要循序渐进的去一步一步的测试得出的结论,对于如何快速插入100w条数据的思考点如下:
在使用多线程批量插入的前提下
1.了解当前业务场景,确定需要执行的任务是什么类型的,如果是内存计算则将核心线程数调整为与cpu相同核心数,如果是做数据传输读写的则将核心线程数调整为cpu核心数的两倍或两倍减一
2.最大线程数则根据业务场景与任务的数据量一边测试一边调整(如果最大线程数设置得较小,意味着线程池的并发处理能力有限,当任务数量超过最大线程数时,新的任务会被放入队列中等待。这可能导致任务处理时间变长。如果最大线程数设置得较大,线程池可以处理更多的并发任务,但也会占用更多的系统资源,可能导致系统负载过高,甚至引发资源耗尽问题。)
3.明确场景后选择合适的阻塞队列,一般来说,性能平衡的任务可以选择固定大小的阻塞队列(ArrayBlockingQueue),有着海量数据的任务则可以考虑使用非固定大小的阻塞队列提高性能以及利用率(LinkedBlockingQueue)
4.在任务执行阶段,需要根据业务数据数量调整分批插入的数据条数,在mybatisplus的批量插入方法中默认为一批1000条数据,根据任务数据量调整至一个合适的分批数量同时还需要考虑数据打大小在网络中传输的影响(是否因为数据量过大导致传输失败或者数据丢失导致插入失败)等问题
5.在上述问题上还需要考虑连接池的配置是否配置合理,当调整线程池以及批量插入条数后发现无法再提高插入效率时考虑是否是因为数据库导致的瓶颈而非线程池与内存,可以使用更为高效的动态调整方式,根据服务运行状态动态的调整连接池的最大连接数。
需要注意的是在以上调整的基础上还需要程序整体的情况,以避免当前服务使用资源过多、资源分配不平衡导致程序出现不稳定的状况。
最后这里放出所有参考到的文章,这篇文章也是在参考和借鉴中完成的,如何快速插入100w条数据的思考也是突发奇想的,在实践与思考中也让自己有所收获
参考文章:
LinkedBlockingQueue与ArrayBlockingQueue阻塞队列详解:https://www.cnblogs.com/lenmom/p/12018347.html
线程池的核心线程数和最大线程数,有什么区别?:https://blog.csdn.net/qq_30939943/article/details/141963740
MybatisPlus实现真正批量插入:https://blog.csdn.net/m0_70871140/article/details/142731767
生产问题之CompletableFuture默认线程池踩坑,请务必自定义线程池:https://www.cnblogs.com/blackmlik/p/16098938.html
spring boot hikari 调试连接池数量:https://blog.51cto.com/u_16175520/11678069
多线程批量插入数据的测试与性能分析,总体性能提升89.2%(讲解的很全面数据对比很清晰):https://blog.csdn.net/m0_64422133/article/details/141422842