
一觉醒来发现DeepSeek突然在热搜持续霸榜,之前有听说过,但是一直没有太关注,直到最近上了热搜,听说可以本地部署,且听说r1-14b的模型和chatgpt3.5不相上下(即使网传3.5的参数最大有1750亿)
据悉,DeepSeek-r1模型本地部署的版本是通过正式版的大模型蒸馏演算结果而得来的,即使是一个lite版本,但是精准度与正式版相差并不大,以下是DeepSeek在github上的介绍与说明:

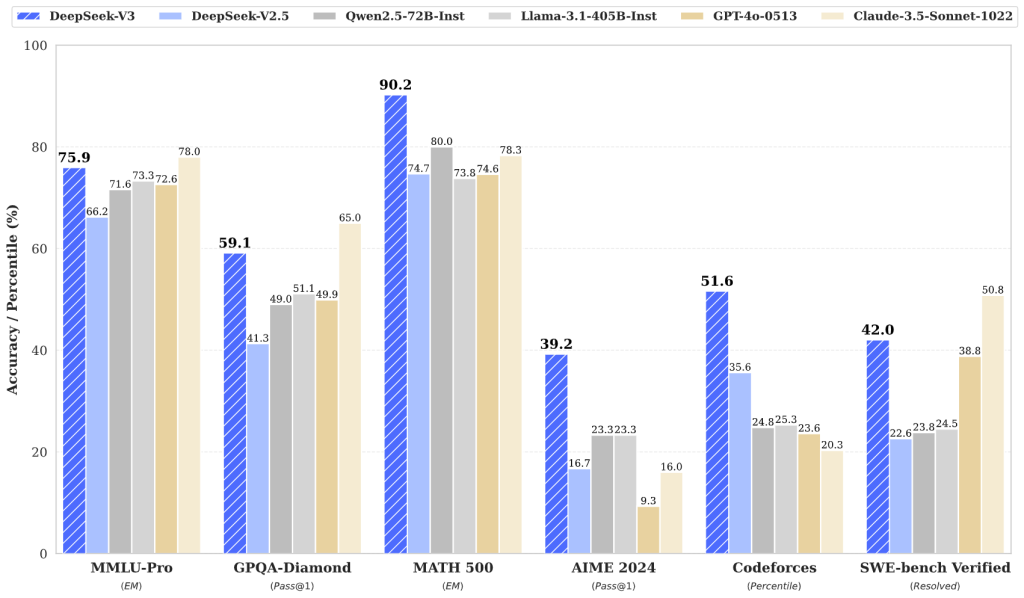
基准测试结果(图片来自DeepSeek的github)
DeepSeek的github地址:
https://github.com/deepseek-ai/DeepSeek-V3/tree/main通过Ollama快速安装与部署DeepSeek-r1模型
在安装之前DeepSeek之前需要先安装ollama工具,通过ollama运行DeepSeek-r1模型。
什么是ollama?
Ollama是一个由Facebook开源的轻量级框架,专为简化大型语言模型(LLM)在本地机器上的部署和运行而设计。它通过 Docker 简化模型管理,占用资源少且具有可扩展性,支持 API 接口、预构建模型库以及从 GGUF、PyTorch 等格式导入和定制模型。Ollama 跨平台支持 macOS、Windows、Linux 和 Docker,适用于文本生成、翻译、问答和代码生成等多种应用场景,特别适合开发者和研究人员快速集成和测试 LLM 功能。
安装Ollama:
官网地址:https://ollama.com/支持多种平台安装,点击下载按钮会进入下载页
选择自己系统的下载项进行下载
因为我这次回家只带了macbook所以我选择的是mac版本,下载后mac版本是一个可执行程序(但其实并非是安装的软件),下载软件后是一个非常可爱的羊驼图标,打开软件界面非常简洁,点击next

导入之后在mac上的命令行工具中粘贴这段命令,可以安装ollama自己的模型(其实可以不用安装,我这里就按照提示进行了安装,发现在M1的mac上响应速度非常快,但是准确度并不是很高)
至此就完成了ollama工具以及llama3.2模型的安装,这时我们可以查看一下ollama工具是否可以正常使用(其实也不用检查,因为如果ollama安装不成功是没有办法通过ollama去安装llama模型的),通过命令行工具输入如下命令查询,如果出现如下信息说明已经安装成功,如果出现不是内外部命令或者出现找不到ollama说明没有安装成功,需要重新安装ollama
ollama -v
安装完成后我们就可以通过ollama run命令对镜像进行拉取并安装,下面提供几个DeepSeek的模型用于安装,按照自己显卡的显存安装,越多参数则表示需要的算力以及显存会更多,同时计算时间也会越长,得出结果的速度也会越慢
# 4G以下显存推荐使用
ollama run deepseek-r1:1.5b
# 8G以上16G以下显存推荐使用
ollama run deepseek-r1:7b
ollama run deepseek-r1:8b
# 16G以上显存推荐使用
ollama run deepseek-r1:14b
ollama run deepseek-r1:32b
ollama run deepseek-r1:70b安装好后最后会提示success,表示安装成功
通过Page Assist插件快速使用安装好的模型:
googleChrome商店插件地址:https://chromewebstore.google.com/detail/page-assist-%E6%9C%AC%E5%9C%B0-ai-%E6%A8%A1%E5%9E%8B%E7%9A%84-web/jfgfiigpkhlkbnfnbobbkinehhfdhndo
github地址:
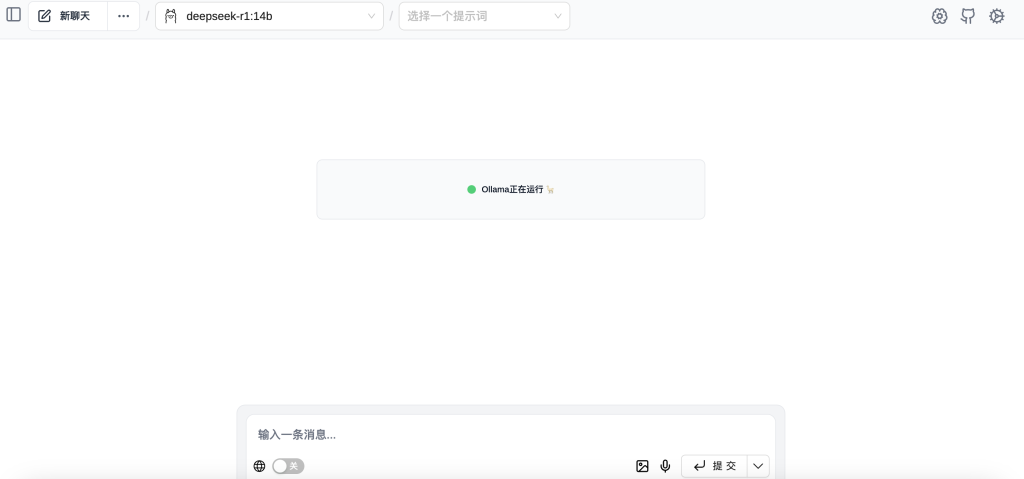
https://github.com/n4ze3m/page-assist安装好后点击图标跳转到Page Assist的Web UI页面,可以在左上角看到现在正在使用的模型,在中间会提示Ollama正在运行 ,这表示Ollama目前是运行状态
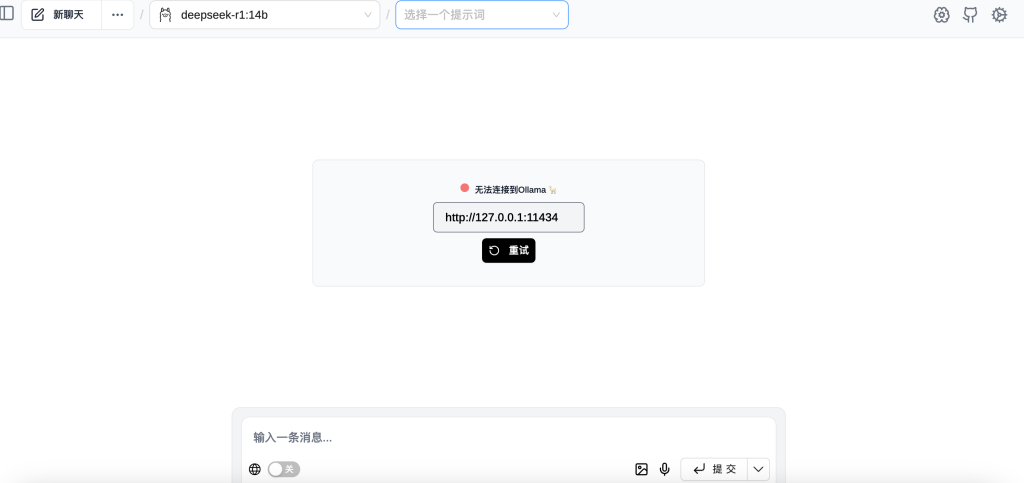
当你关闭了Ollama软件后则会显示无法连接到Ollama
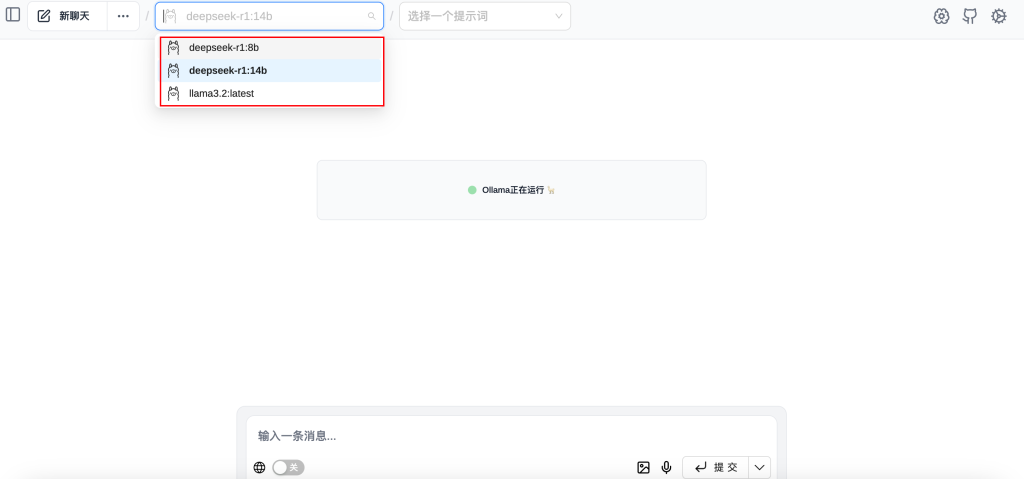
右上角选择自己安装好的模型后就可以和chatgpt那样正常与它聊天啦
至此,DeepSeek-r1模型的快速安装与使用就完成啦