首先安装python环境,官网地址:Python Releases for Windows | Python.org
根据个人电脑系统下载对应的安装包
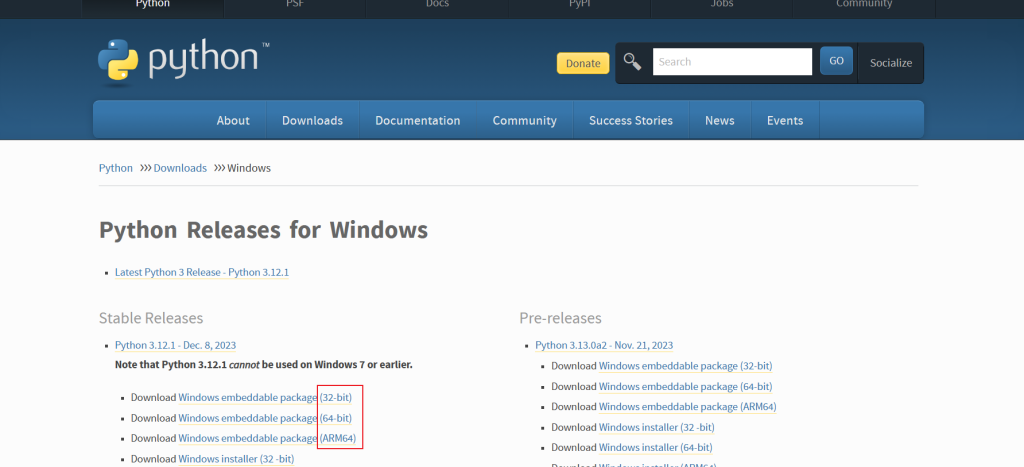
注意:一定要勾选下面的 Add Python x.x to PATH,若不选这一项,则后面需要手动配置环境变量,很麻烦。然后点击 Install Now
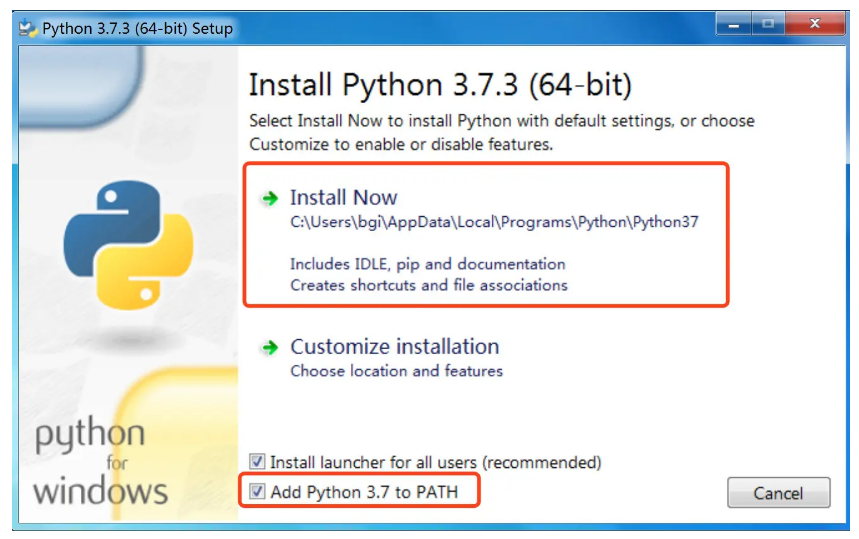
安装好之后可以在cmd中测试是否已经可以使用python命令

如果有如上图中展示出了版本信息,说明已经安装好了python的环境。
然后可以安装PyCharm,在PyCharm中进行编码,官网地址:Download PyCharm: Python IDE for Professional Developers by JetBrains
如果使用pip install 命令无法下载指定的某些库,可以尝试在 user 目录中创建一个pip目录,如:C:\Users\xx\pip ,新建文件 pip.ini,配置国内的镜像地址
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
如果是内网环境,可以使用代理下载指定的某些库
pip install --proxy http://<代理服务器地址>:<端口号> xxx(需要下载的库名)这里是自己写的一个小案例:
思路:获取百度热搜的链接->通过链接获取连接中的热搜数据(包括标题、简介、热度、链接)->将获取到的数据存放到excel中用于下一步在bi中做展示

代码如下:
import pandas as pd
import requests
from bs4 import BeautifulSoup
import datetime
import os
# 设置代理
proxies = {
'http': 'http://<代理服务器地址>:<端口号>',
'https': 'http://<代理服务器地址>:<端口号>'
}
# 请求头部信息,模拟浏览器请求
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
}
# 百度热搜榜地址
url = 'https://top.baidu.com/board?tab=realtime'
# 发起网络请求
response = requests.get(url, headers=headers, proxies=proxies)
# 解析页面内容
soup = BeautifulSoup(response.text, 'html.parser')
# 获取热搜榜列表
hot_list = soup.find_all('div', {'class': 'category-wrap_iQLoo horizontal_1eKyQ'})
# 创建空的数据列表
data = []
# 遍历热搜榜列表并获取标题和热度
for index, hot in enumerate(hot_list, start=1):
# 获取标题
hott = hot.find('div', {'class': 'c-single-text-ellipsis'})
# 获取简介
hottinfo = hot.find('div', {'class': 'hot-desc_1m_jR small_Uvkd3'})
hottinfo = hottinfo.get_text(strip=True) if hottinfo else '未获取简介'
# 获取热度
hot_rank = hot.find('div', {'class': 'hot-index_1Bl1a'})
hot_rank = hot_rank.get_text(strip=True) if hot_rank else '持平'
# 获取标题
hot_title = hott.get_text(strip=True)
# 获取链接
hot_link = hot.a['href']
print(f'{index}. 热度:{hot_rank}\t标题:{hot_title}\t简介:{hottinfo}\t链接:{hot_link}')
# 获取当前日期
current_date = datetime.datetime.now().strftime('%Y-%m-%d')
# 获取当前日期和时间(精确到秒)
current_date_time = datetime.datetime.now().strftime('%Y-%m-%d-%H-%M-%S')
# 创建以当前日期和时间为名的文件夹在D盘根目录下
folder_path = os.path.join('D:\\百度热搜', current_date) # D盘根目录的路径
# 创建以当天日期为名的文件夹
os.makedirs(folder_path, exist_ok=True)
# 将获取的数据添加到数据列表中
data.append([index, hot_rank, hot_title, hottinfo, hot_link])
# 将数据转换为 DataFrame 对象
df = pd.DataFrame(data, columns=['排名', '热度指数', '标题', '内容简介', '链接'])
# 将 DataFrame 写入 Excel 文件
file_path = os.path.join(folder_path, f'hot_search_{current_date_time}.xlsx')
df.to_excel(file_path, index=False)在如上代码中,进行了热搜信息的输出打印,并且对获取的excel进行了存储,以当前日期为文件夹进行每天数据收集,以当前时间(到秒)为文件名称后缀,获取到的文件不重复,可根据自己的需求进行定时调度。
如果不报错的话就可以获取到一些热搜的数据

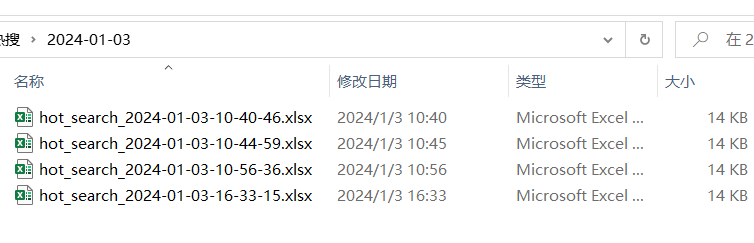
获取到想要的数据后可以使用帆软bi进行数据展示(我使用的是试用版),官网地址:FineBI安装与启动- FineBI帮助文档 FineBI帮助文档 (fanruan.com)

进入分析界面后,可以选择新建分析主题的文件夹或是直接新建分析主题
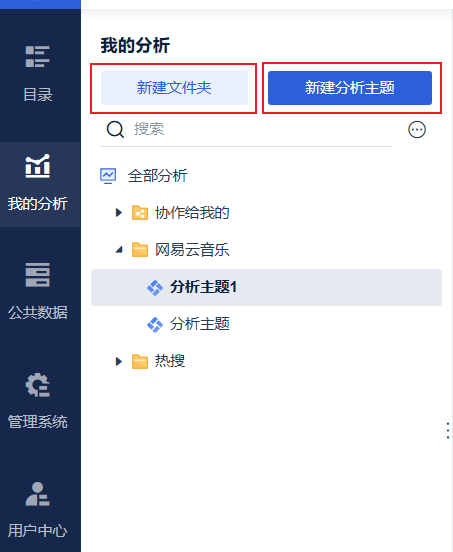
点击新建分析主题后可以选择本地excel导入,将刚才获取的数据的excel上传到这里
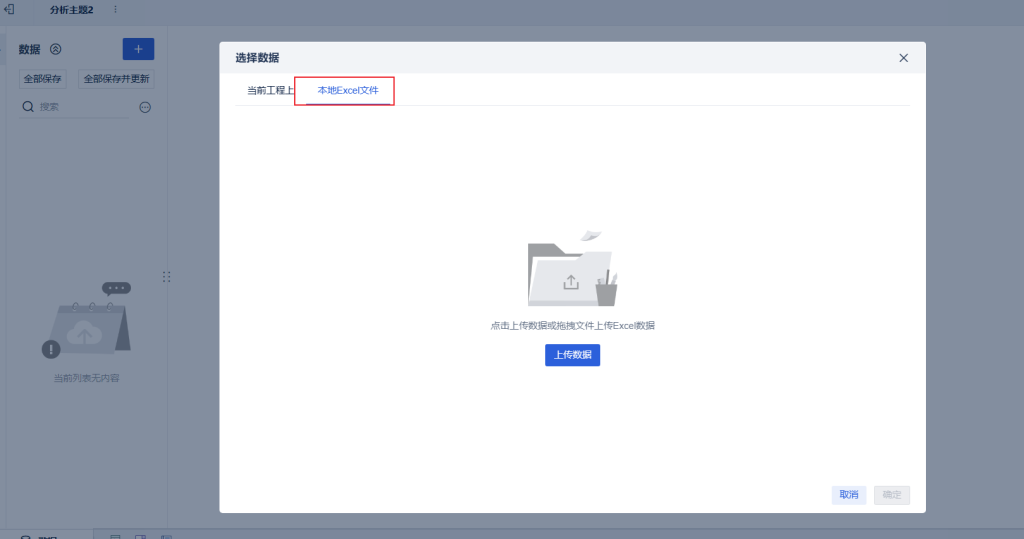
调整好字段类型就可以点击确定了

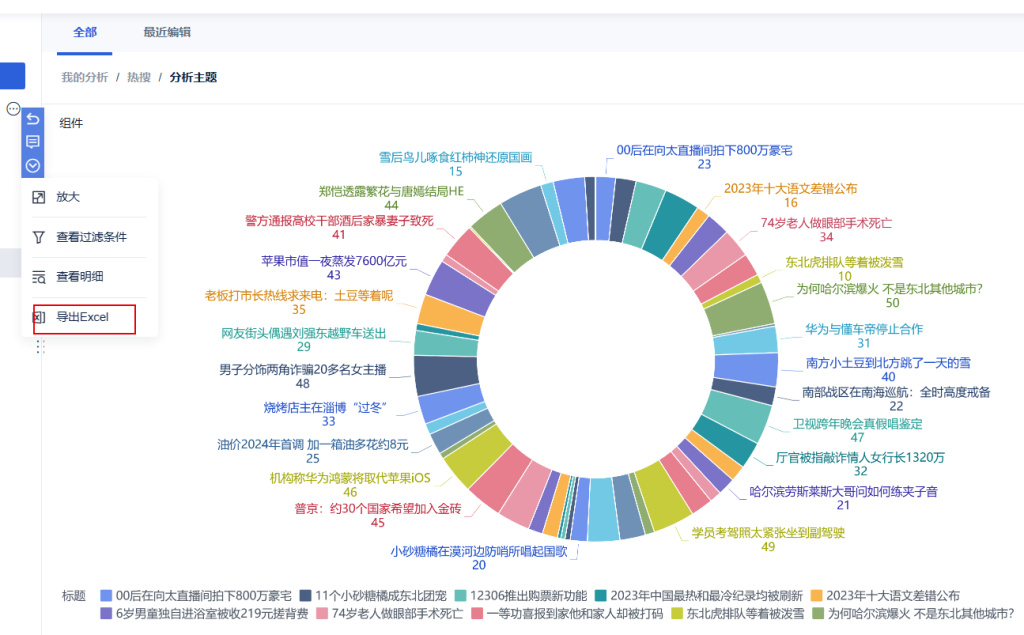
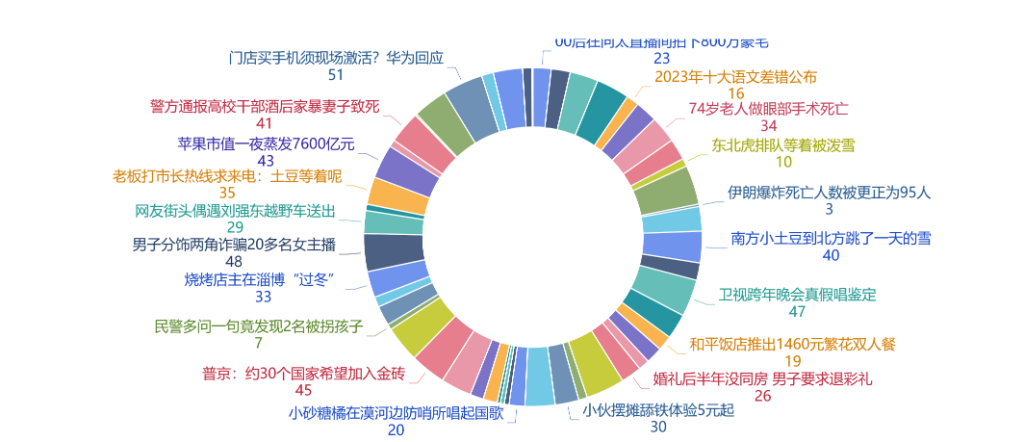
点击下方的组件进行组件选择和数据展示
左边上面可以调整图表类型,下面可以调整属性和样式,可以根据个人数据不同意义的维度度量值进行选择和更改
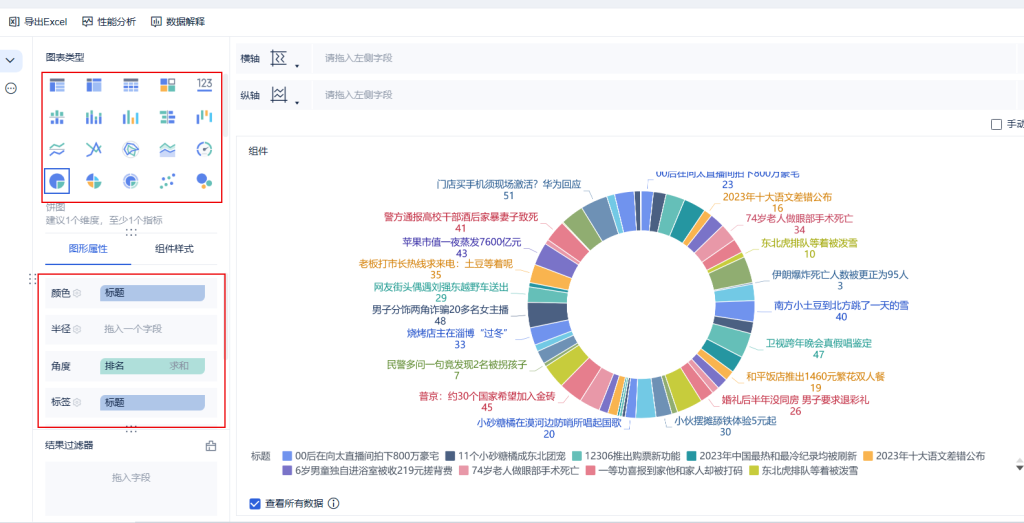
最后可以导出编辑好的数据和组件