
问题:前段时间写的热搜小demo后来想了想每次都需要手动执行,且还需要整理维护每天的excel文件数据,相对来说比较麻烦,而且如果数据多了后期想维护还是放到库里比较好。所以对上次的demo做了一些调整。
在之前热搜原有基础上增加了自动生成sql并导入数据库的操作,在这直接如果还是需要存储excel的话之前的代码可以保持不变。
如果不再需要存储excel的话可以去除保存excel的代码部分
# 获取当前日期
current_date = datetime.datetime.now().strftime('%Y-%m-%d')
# 获取当前日期和时间(精确到秒)
current_date_time = datetime.datetime.now().strftime('%Y-%m-%d-%H-%M-%S')
# 创建以当前日期和时间为名的文件夹在D盘根目录下
folder_path = os.path.join('D:\\百度热搜', current_date) # D盘根目录的路径
# 创建以当天日期为名的文件夹
os.makedirs(folder_path, exist_ok=True)
# 将数据转换为 DataFrame 对象
df = pd.DataFrame(data, columns=['排名', '热度指数', '标题', '内容简介', '链接'])
# 将 DataFrame 写入 Excel 文件
file_path = os.path.join(folder_path, f'hot_search_{current_date_time}.xlsx')
df.to_excel(file_path, index=False)需要注意的是数据列表的代码别注释或者删掉了,这个留下来还有用(下面用它做变量生成sql使用)
# 将获取的数据添加到数据列表中
data.append([index, hot_rank, hot_title, hottinfo, hot_link])以上是原有代码,下面的思路是根据上面获取到的数据列表中的数据拼接成sql,通过pymysql库连接数据库(我这里使用的是mysql),构建好sql后需要先做查询操作,以标题和链接为条件查询数据库中是否存在对应数据(这里的意思是我并不需要反复存储所有数据,之前想的方案是先删除数据库表中所有的数据然后再插入新的数据,但是这样就只能获取当天的那十几条数据,并且后面也不会累计,这样收集到的数据对于分析来说意义不大,所以对这部分逻辑进行了改进),通过对已经存在的数据进行查询,获取到和本次获取到的热搜数据相同的数据,对这部分数据进行删除(就是数据库中存储的老数据,这里暂时存储的是这条热搜最后在榜的记录),然后再进行插入操作。
连接数据库的代码建议写在循环外提高复用性,我写在了最开始的地方用于初始化
# 连接MySQL数据库
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', database='mysql')
cursor = conn.cursor()这是后半段新增的代码
# 遍历获取的数据,生成插入语句并执行
for item in data:
index, hot_rank, hot_title, hottinfo, hot_link = item
# 构建查询语句,以标题和链接为条件查询数据库中是否存在对应数据
check_query = f"SELECT COUNT(*) FROM baidu_hot WHERE hot_title = '{hot_title}' AND hot_link = '{hot_link}'"
cursor.execute(check_query)
result = cursor.fetchone()
# 如果存在数据,执行删除操作
if result and result[0] > 0:
delete_query = f"DELETE FROM baidu_hot WHERE hot_title = '{hot_title}' AND hot_link = '{hot_link}'"
try:
cursor.execute(delete_query)
conn.commit()
except Exception as e:
conn.rollback()
print(f"删除数据失败:{e}")
# 检查数据是否已被删除,如果是,则执行插入操作
check_deleted_query = f"SELECT COUNT(*) FROM baidu_hot WHERE hot_title = '{hot_title}' AND hot_link = '{hot_link}'"
cursor.execute(check_deleted_query)
deleted_result = cursor.fetchone()
if not deleted_result or deleted_result[0] == 0:
insert_query = f"INSERT INTO baidu_hot (ranking, hot_rank, hot_title, hottinfo, hot_link, create_time) VALUES ({index}, '{hot_rank}', '{hot_title}', '{hottinfo}', '{hot_link}', NOW())"
try:
cursor.execute(insert_query)
conn.commit()
except Exception as e:
conn.rollback()
print(f"插入数据失败:{e}")
else:
print(f"数据已被删除:标题:{hot_title},链接:{hot_link}")
# 关闭数据库连接
cursor.close()
conn.close()通过以上的操作就可以将获取到的数据存入数据库中,并且每天会累计存入上榜的数据,所以接下来要解决的问题是,如何定时调度。
我这里因为使用的是宝塔面板,所以我使用了宝塔自带的计划任务工具,这里需要创建一个计划任务用于调度
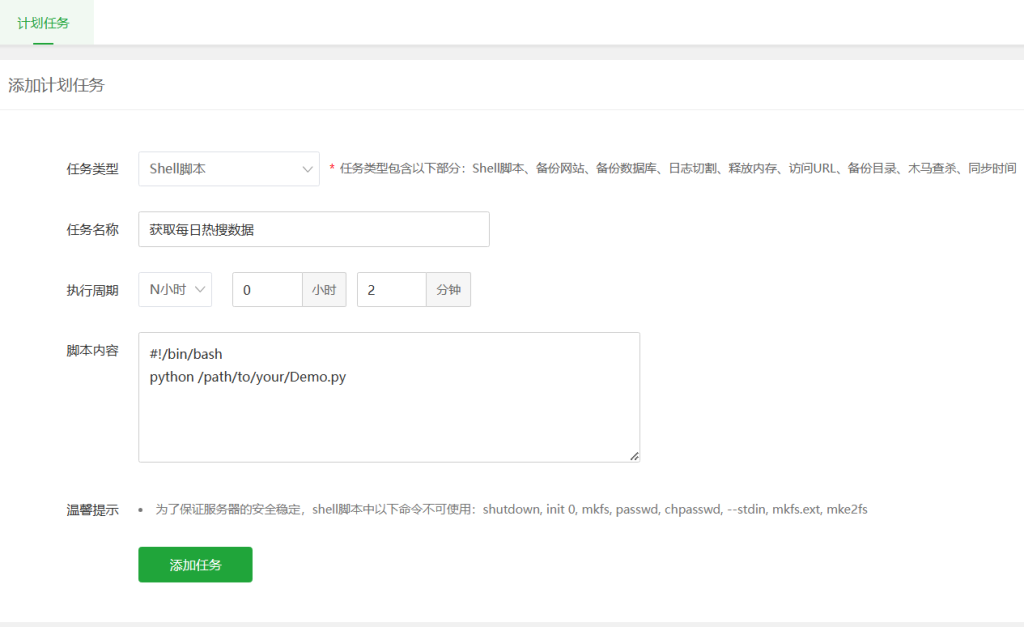
这里需要创建一个shell脚本用于运行编写好的程序,起始格式为#!/bin/bash,python为固定格式,/path/to/your/为这个python程序所在的路径,script.py为你编写好的程序
#!/bin/bash
python /path/to/your/script.py设置好调度周期点击添加任务就可以定时调度了
这里有几点注意事项:
如果你使用的不是宝塔面板,如果使用的是centos可以使用centos自带的调度功能
使用以下命令编辑 cron 表
crontab -e在 crontab 文件中,可以按照以下格式添加 cron 作业的规则
* * * * * command_to_be_executed其中,星号(*)表示每个时间段,每个星号对应一个时间维度(分钟、小时、日期、月份、星期),你可以根据自己的需求编辑cron表达式,也可以通过百度搜索cron表达式在线生成网站进行生成
例如,要在每天的上午10点运行一个脚本(这将在每天的上午10点(小时=10,分钟=0)运行名为 your_script.sh 的脚本)
0 10 * * * /path/to/your_script.sh编辑完成保存后cron 作业将会自动生效,可以通过一下命令来操作cron 作业
crontab -l #查看当前用户的 cron 表
crontab -e #编辑当前用户的 cron 表
crontab -r #删除当前用户的 cron 表另外需要注意Python版本如果不通代码的编写方式也不太一样,有些编写方式在低版本的Python环境下是无法运行的(我这里本地环境是3.8.10但是我的服务器环境却是2.7.5,代码在服务器上无法运行)
我这里遇到的问题是:
UnicodeEncodeError: 'ascii' codec can't encode characters in position 28-38: ordinal not in range(128)这个问题的原因是由于在使用 Python 2.x 版本,而在 Python 2.x 版本中,print 语句会尝试对 Unicode 字符进行编码,如果未指定编码方式,就会使用默认的 ASCII 编码。在代码中,由于包含了中文的 Unicode 字符,导致了这个编码错误。包括如果代码中存在中文注释也会有相似的报错。所以我的解决方案是,为程序添加默认字符集编码规则(设置默认的编码方式为UTF-8)
# -*- coding: utf-8 -*-在添加默认编码方式的同时将Unicode 字符转换为字符串(在字符串前添加 u 来表示Unicode),例如:
#Python 3.x 版本
print('{0}. Hot Rank: {1} Title: {2} Description: {3} Link: {4}'.format(index, hot_rank, hot_title, hottinfo, hot_link))
# Python 2.x 版本
print(u'{0}. Hot Rank: {1} Title: {2} Description: {3} Link: {4}'.format(index, hot_rank, hot_title, hottinfo, hot_link).encode('utf-8'))
通过以上方式就可以将代码运行在服务器上了,这样就可以获取每日大多数时间段的热搜数据,收集的数据可以通过上次使用的帆软bi进行数据分析或大屏展示。